Boxedwine as a path to running Tribes 2 in a web browser
Two months ago the Boxedwine project (https://github.com/danoon2/Boxedwine) came on my radar (after it was posted to Hacker News). It's a combination of a new emulator for 32-bit Intel x86 CPUs (of the Pentium 3 vintage), a Linux shim layer (ELF loader & partial system call implementation), and Linux builds of the Wine project (stock-ish 5.0) that can run on Windows, Mac OS, Linux, and also in the browser (via Emscripten toolchain).
It's borderline insane, but in short, it's a way to run unmodified Windows applications that supports standard web browsers. It piqued my interest, because it creates a path to being able to run Tribes 2 in the browser without installation, and creates a sustainable method of running the game as computers rapidly lose compatibility with early 2000s 3D games (modern GPU drivers on Windows isn't even a sure thing for this game anymore). With some extra work, this can even include multiplayer, as well as single-click URLs to join games.
However, I do want to temper expectations, because this won't be ready to fly any time soon. I built a version of this for my MacBook (Air Mid-2020 Intel), and have some findings.
The good:
- Installation from the stock GSI "just works"
- Launching the game (in LAN mode) also mostly "just works"
- Switching graphics resolution, window size, and such seems table
- I was able to load a training mission and get in game
- No crashes except when closing the game
The bad:
- Graphical glitches, specifically vertex errors (texturing looks fine)
- Sound, garbled; I turned it off as quickly as I could
- File reading/writing is extremely and abnormally slow (loading the training mission took over 10 minutes, and installing the game itself took about 25-30 minutes from the GSI)
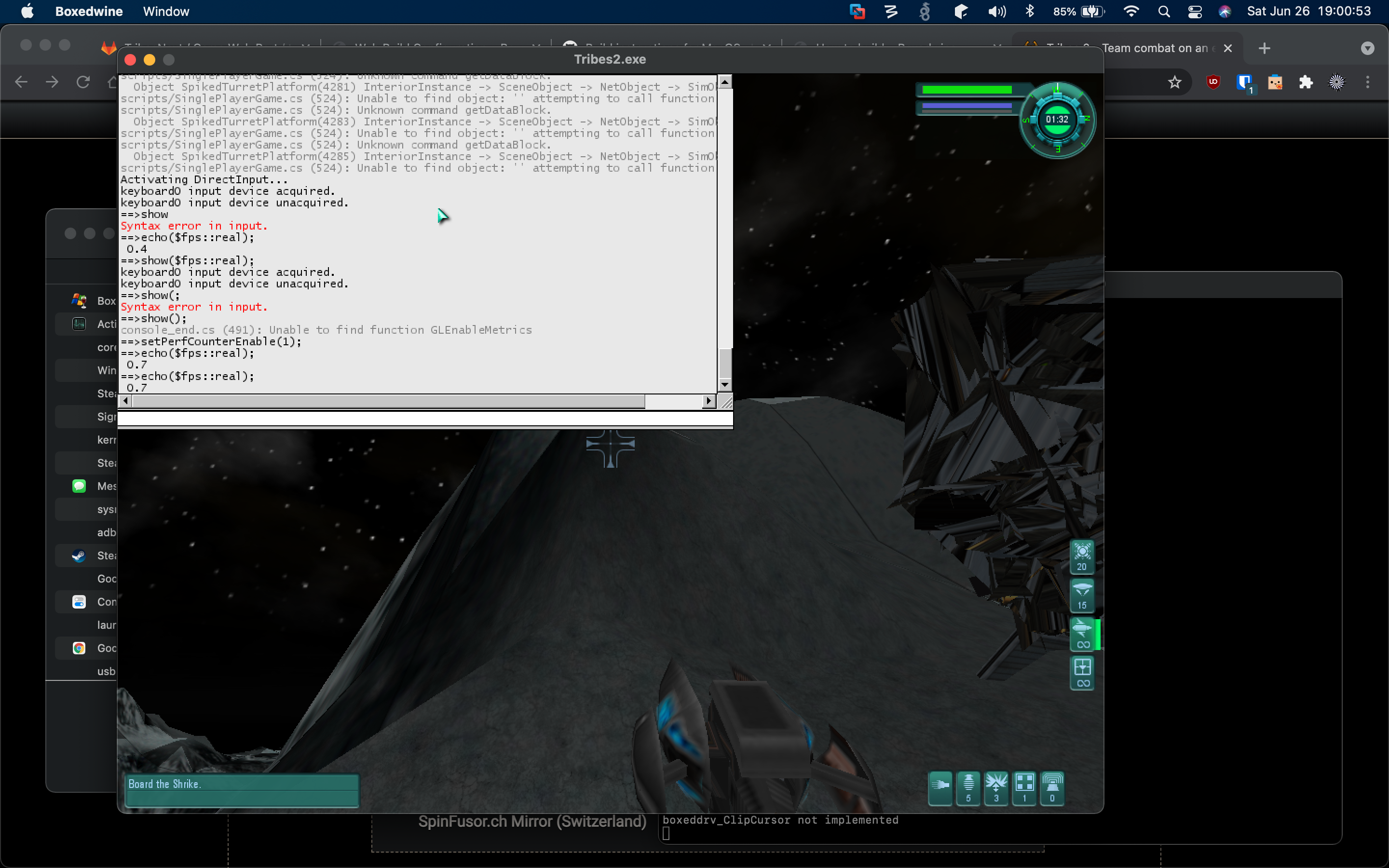
- (The real kicker) performance was atrocious at about 0.4-0.7 frames per second in game
My intuition is that the frame rate is somehow tied to the way the game polls the mouse input device when in game, since I'm getting between 30 and 60 frames per second in the game UIs, and not from the compute requirements of game logic or the rendering pipeline. I remember that T2 always had a tendency to spin-loop a full CPU core, rather than yielding when done for a game tick -- this might be especially bad when using this CPU emulator, and could be resolvable by additional patches to the game.
As a silver lining, though, my Mac build of Boxedwine used the slowest emulator mode (interpreter; no JIT), which I guess shouldn't be too far off from the possible WebAssembly performance (which might be only 10-20% slower).
I've attached a few screen shots from my experiment this evening.
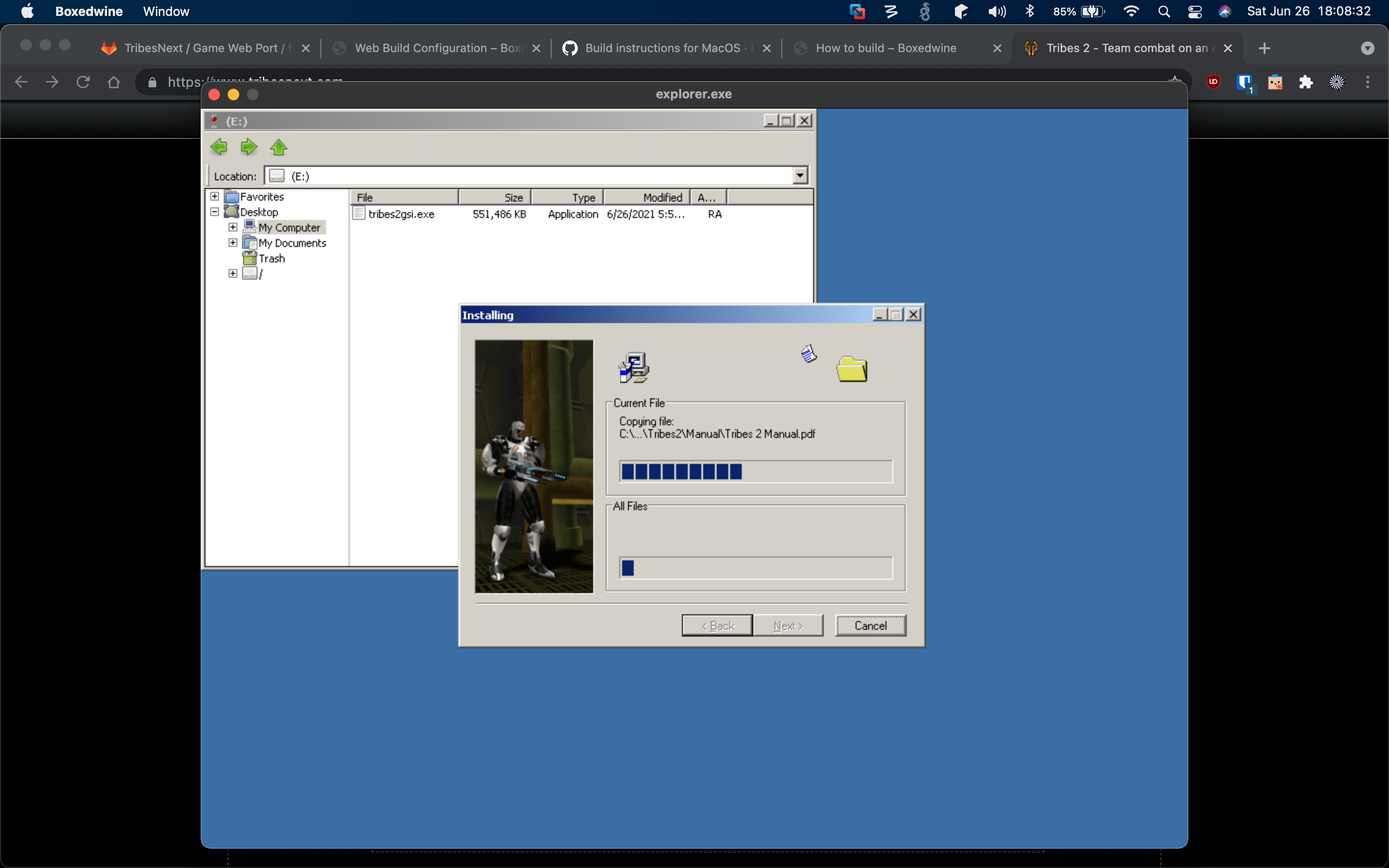
Installing the game via the Wine-provided Explorer clone:
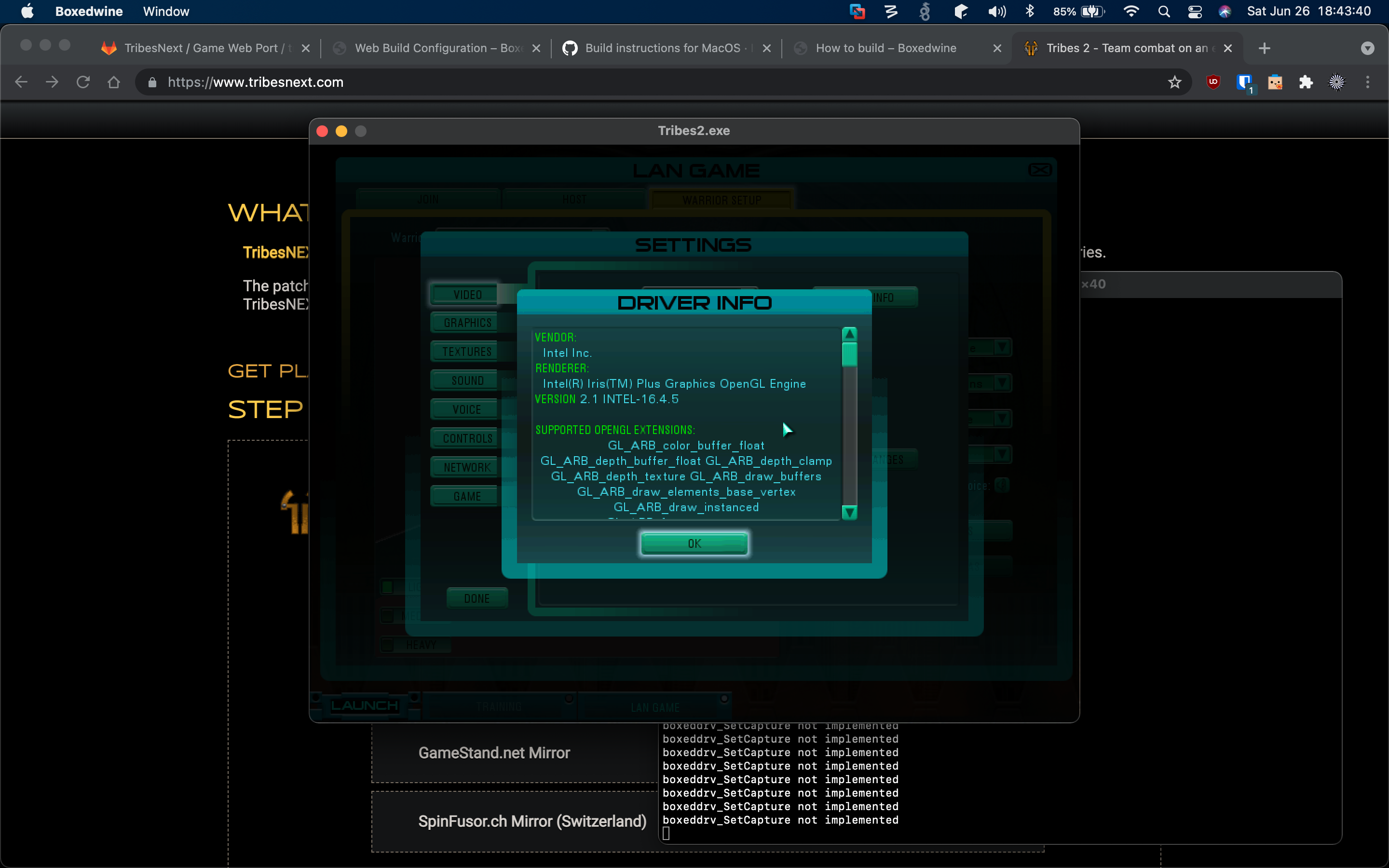
OpenGL and extensions as the game saw them on first launch:
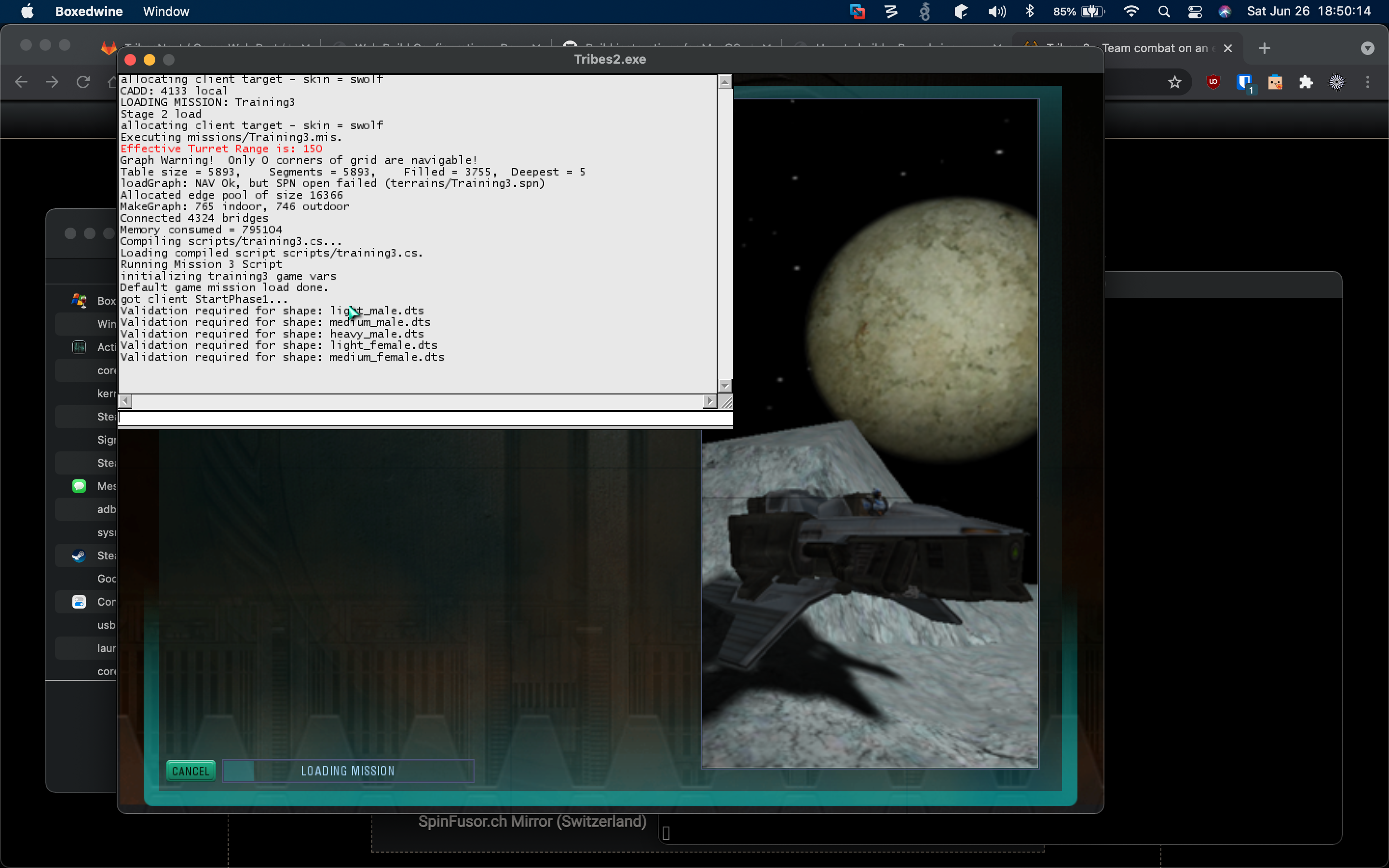
Loading Training Mission 3:
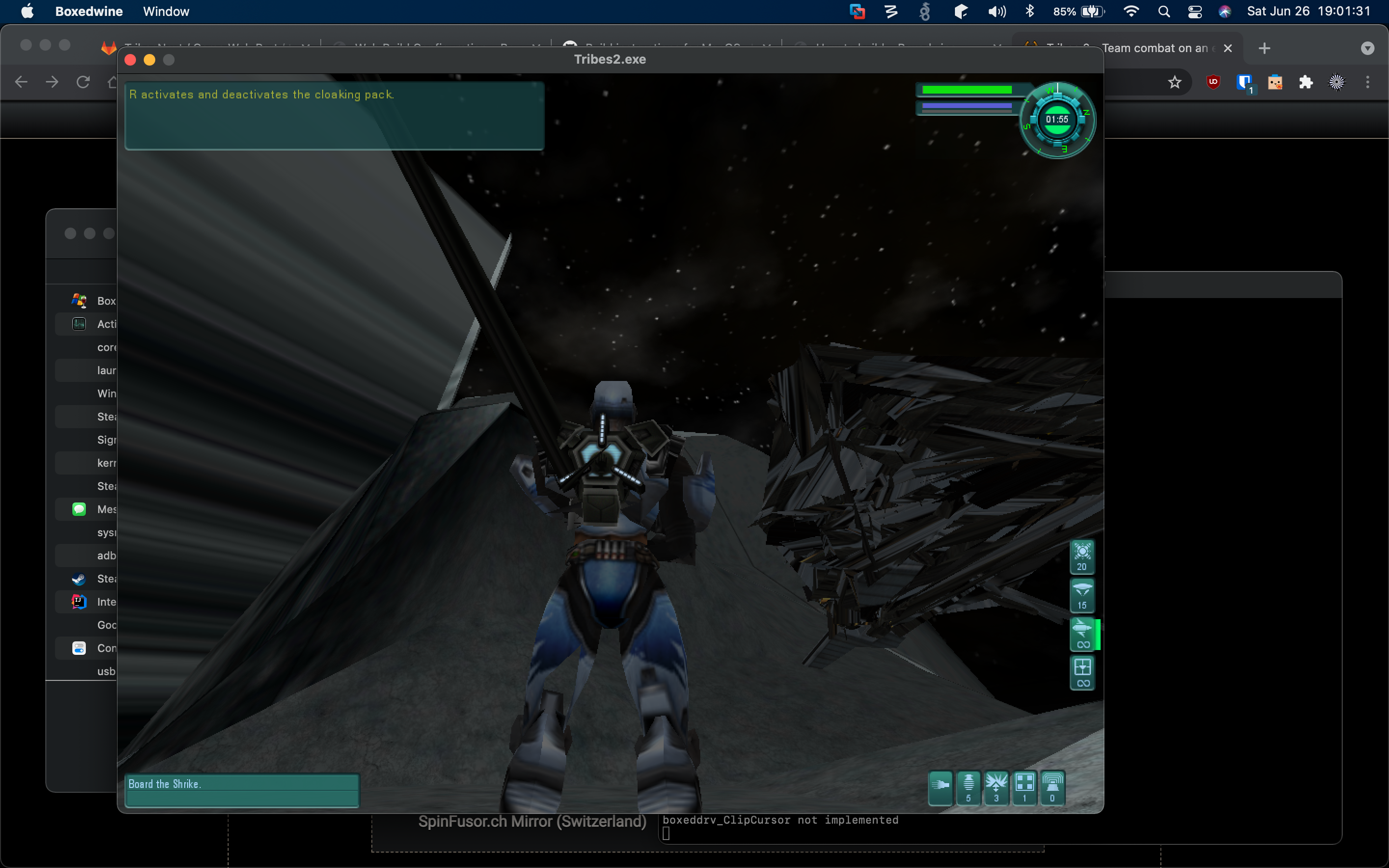
In game, with graphical glitches:
Console showing how bad the frame rate is in game:
Not too terrible FPS in UIs:
Broadly, this is the list of action items that would have to be solved for this to ever get off the ground:
- Test the game in Boxedwine on a non-Mac to see if the graphical glitches are just down to Apple's garbage OpenGL driver [Easy]
- Hack the game so that it yields the CPU when it is done with its work for a tick, rather than it spinning at full speed (and any other work on perf-counter/etc. to make it work better under the Pentium 3 emulator) [Hard]
- Get Boxedwine to support legacy OpenGL 1.x (fixed-function pipeline) graphics in the browser (WebGL is based on OpenGL ES 2.0+, which is programmable pipelines only) [Hard]
- Try running the game in a browser Boxedwine build [Easy?]
- Build networking shim for the browser build (translate connections made by the game in emulation to WebSocket and/or WebRTC APIs so it can talk to game servers and TribesNext services) [Medium]
- Build a companion app to run along side T2 servers so that browser clients can connect (WebSocket and/or WebRTC proxy) [Medium]
Would be cool if we could get it working. Those two "Hard" items are quite brutal though.
Comments
Hmm, I don't think it should be blocked by the message loop input polling unless they've made some unusual changes in their Wine fork: the game uses PeekMessage rather than GetMessage, so it should return and continue processing immediately regardless of a signal being present in the queue. When it's handling the devices with DirectInput, I believe the biggest difference should just be that it has doing some abstraction handling the event data in its own thread, so the game might be saving time on the main thread not having to process everything.
The game does however sit and wait ~100ms for input if it thinks it's not the foreground window, which you could try
memPatch("560BBC", "EB3B");to bypass for sanity's sake. That'd definitely be a huge limiter if it's not detecting it being the foreground process correctly.By default the game does ostensibly attempt to yield by calling Sleep 0 when in client mode, which in practice does effectively just end up spinning it nearly all of the time... but on Windows with the standard timer resolution anything more they had available waits a minimum ~15.6ms before returning control to the thread for the next iteration, which isn't ideal -- especially with how inaccurate the Windows GetTickCount() is and how many game/physics ticks are skipped as a result.
Under Wine the timer resolution is always 1ms and GetTickCount is more reliable, so simply changing the Sleep call to 1 could be an effective way to free it up a little and save power. It would add an additional millisecond after everything from the previous frame is complete before input is processed again of course, so might not be the best control response feel if there isn't a stable render time. Not that it's benefiting from an immediate response as it is now.
I'll probably try building boxedwine under Windows and give running it a shot later.
My initial assumption based on the screenshots alone was the biggest FPS hitch you're hitting in-mission is the terrain rendering: since every frame, for every tile in view, the game is dynamically generating that mesh from the heightfield, and for every tile that hasn't already been cached it's doing software blending of the various textures and shadow map. Depending on the settings and extensions it might've detected as being supported it possibly could also be behaving in a way that's not working so well in that GLES emulation of the pipeline, or the number of GL calls may be bottlenecking it, but mainly it's something that I'd imagine would be difficult for it to keep up with in interpreter mode. It was certainly one of the main causes of performance issues people with older systems had at release.
I'd be curious to see how big of a difference there is with the terrain removed, in addition to comparing an interior in/out of view (given they're the next most complex rendering item but a much lower CPU load).
If you can make this work eventually, it should bring quite a decent amount of new players in as well. While I dislike playing games in a browser myself, I can see a lot more people giving T2 a try just because it's so easy to play. I've seen another old game rebuilt so that it's playable in a browser and it had a lot of success. I'm not technically knowledgeable enough to comment on the specifics here but I think this could be great for Tribes 2. Hope it can be done!
The input loop thing was just a guess. The dynamic terrain height field calculation could definitely be a factor; it would also partly explain why the corrupted visual geometry changes from frame-to-frame -- a lot of that geometry is being recomputed (and resent to the GPU) each frame. Hard to know definitely what's slowing things down without a profiler of some kind.
Something is definitely off in the game's internal timers though, which is why I suspected the hot spin looping. I was using the show command with $fps::real to try to get a continuous display of a frame rate, but was getting a mix of 0's and values in the 100s and 1000s.
I'll also make an attempt at building a Windows version and seeing what it looks like on a Xeon E5-2630v3 / GeForce 1080 Ti.
I should note that there are two independent aspects of emulation under Boxedwine: (1) CPU emulation, and (2) OpenGL emulation. There are 3 CPU emulators (of x86 on x86, at least) in Boxedwine: (a) interpretation (slowest), (b) JIT, and (c) binary translation (fastest). The Mac build I assembled AFAIK supports only CPU interpretation, and this would continue to be a limitation for WebAssembly builds. The OpenGL side, however, was using the native passthrough to system OpenGL and not including any emulation of legacy pipeline on GLES, so should be about as fast as it gets (and also exposed to any OpenGL driver bugs, of which Mac OS is particularly notorious). I didn't see much of a point jumping straight to the browser with software rendered or otherwise hacky OpenGL until getting a taste on the Mac.
Be aware of that if you make a Windows build, I think it'll default to running CPU under binary translation, which would be much faster.
Having source code to the game would give us so many more options here (i.e. directly using Emscripten toolchain). WebAssembly may eventually gain an API for accelerating internal JITs, which could enable a Boxedwine JIT core variant. In theory, since T2 doesn't do (much/any?) self-modifying code (except for the stuff we're patching in TribesNext), an emitter of WebAssembly that partially evaluates the code running under emulation (i.e. the first Futamura projection of T2 under Boxedwine) could grant the same kind of speed as the binary translator core, but I'm not suggesting it seriously, since it'd be impractically insane.
Whoops, yeah, had GLES on the mind a bit early there. Those vertex glitches did have me thinking though, and it does appear boxedwine's opengl wrapper could potentially have issues with some of the game's behaviour: at a glance it mainly appears to be copying buffers to native memory on every pointer-related gl call (possibly a performance hit but probably not catastrophic?), which I think should be safe if the data were static, but in theory the game modifying the buffers after these pointer calls and before GPU sync would result in undesired effects. Just a spitball though, might have to run some basic validation on those extracted buffers at the stage immediately before they'd be loaded into GPU memory to test that they match what's in the game's memory.
I've done work on replacing the timers in the past, and they're a relatively easy fix if they're a big problem. Mainly just a case of replacing the functions for querying the total real tick count and the time manager bit that pumps tick events to the game. Could be that what it's reporting is a result of how much time is passing between frames though, I know they attempt to do some averaging in that variable, and the calculation might not be accurate for less than a frame a second.
I compiled the default configuration over lunch and did some very limited testing, found a couple things:
Will give it another look sometime this week to try to get it at least in a mission, and to see what other insights might be found in changing how the emulator is set up.
It's strange that networking is behaving differently when on a Windows host. I did notice that the addresses showing up in the console (including in my last screenshot) were IPX addresses, which was amazing in its own way (a completely dead protocol now, even though games of that era were compatible), but otherwise had no problems getting into the training missions or launching a listen server and joining a team.
I was definitely getting SOME sound from the Miles 2D audio driver -- the various bleeps and bloops of the UI buttons, but they were scrambled and constantly repeating fragments of the audio.
I'm pretty noob at Xcode, so a slow file I/O debug build when testing is definitely possible.
Since the OpenGL glitches look to be an issue with Boxedwine, and I've (at least a little) unfairly maligned Apple's OpenGL driver, I'll file a bug with the Boxedwine upstream this weekend.
I gave it a quick try with Miles re-enabled again and it didn't have audio at startup, but the menu ambient and bloops would play if I caused it to reset (e.g. by changing the bitrate in the options). Whenever I'd open the options again, the audio would stop. Maybe something's causing the audio handler thread to terminate? Hmm.
Not sure about the networking yet, going to try throwing a test or two at it later. It'll be using the Wine winsock->unix implementation within the emulator, but ultimately passing through boxedwine's native socket adapter back to winsock on a Windows host... there isn't a ton of deviation between unix sockets and winsock though, so I wouldn't expect something as basic as binding to cause issues. I do have multiple network adapters on the test system though, which could possibly be the problem.
Since the game is almost entirely doing playback of static WAV files (with playback speed adjustment/support for 3D positional audio), and static MP3 music, with only the built-in microphone voice chat for dynamic audio (which AFAIK nobody has used recently), intercepting and bridging audio playback to browser WebAudio APIs could be a way of solving that and removing the need to emulate a Windows compatible audio stack entirely.
Such an audio implementation could read out of the VL2 ZIP files on demand and cache the audio data for triggered playbacks.
I'm increasingly realizing that just dropping the game in Boxedwine and hoping that the emulation will both be sufficiently correct and high performance isn't super plausible. Networking will need a browser side bridge to WebSocket, WebRTC, and/or XHR APIs already anyway. The way the audio data is stored in game files and relative simplicity of blitting WAVs out of the ZIPs makes it relatively uncomplicated to bridge audio in the browser similarly.
I'll still play around with a Windows build on my end as well, and try to replicate your networking issues.
Yeah, the audio system should be entirely async anyways, so bridging those calls elsewhere should be totally doable. The WebAudio API does also have some spatialization support, so positional data wouldn't have to be tossed out going that route either.
Turns out I was at least partially mistaken about local connections not working. The game attempting to bind port 0 on startup caused it to lock up, as did "success" in binding an external/native port. Trying to binding a port that's already in use (and getting the error 5 response) allowed it to continue and load into the mission.
Unfortunately, although I was able to load into missions, it would only run for a few seconds before crashing if there happened to be a terrain in the map (no wine/seh exceptions, probably boxedwine gl related). Without a terrain it seemed able to run indefinitely.
TCP objects don't appear to work either --
KNativeSocketObject::setsockopt level 0 not implementedis reported in the log on attempting use, so it must be failing to set the buffer size. Probably an easy fix, but that one wouldn't really be a problem in a browser.I wonder if that setsockopt issue or a similar altered/unimplemented setup value could be the cause to the UDP binding problems, come to think of it. The game is sending 0xffff in the level argument for every direct call it makes to that function, yet that error is also reported in the log when binding a port. If the socket is still in blocking mode or doesn't have the buffer set up by the time recv is called, that might explain a few things.
I haven't poked at this in the last month, but I also came across this project: https://github.com/copy/v86 -- it emulates a CPU of similar Pentium 3 vintage as Boxedwine (though includes SSE2, which was added in the first Pentium 4), but does dynamic recompilation of the x86 machine code to WASM (i.e. an x86->WASM JIT) rather than interpretation. The x87 FPU instructions are done via soft-FPU emulation; this gives identical results as real Pentium 3 (for Intel's 40-bit/80-bit extended precision floats), but probably very slow relative to just passing through to native FP instructions in WASM.
I think Tribes 2 can make use of SSE instructions instead of x87 (e.g. if masked off on CPUID), which are IEEE 754 compatible (and apparently mapped to native FP instructions by v86). Even if not, an imperfect emulation of x87 via IEEE 754 FP instead of a precise soft-FPU might be good enough (since the game network protocol should correct minor FP deviation/error to whatever the server's authoritative values are).
The v86 project is a full system emulator, rather than a user space emulator like Boxedwine, but the x86 to WASM JIT might be adaptable to use in the latter without also pulling in everything else. Since v86 is BSD 2-clause licensed, and Boxedwine is GPLv2 licensed, the direction of copying v86 code into Boxedwine is copyright acceptable. A non-trivial integration task, but it would probably bring CPU emulation performance high enough to support playability of T2 in the browser. Easier than writing an x86 -> WASM JIT/BT from scratch for Boxedwine.
Beyond that, we still would have to resolve the OpenGL graphical glitches seen in Boxedwine, and make accelerated OpenGL 1.x work when bridged to WebGL.
v86 is pretty cool, I remember fiddling with their web examples a few years ago when it was making the rounds because somebody had posted about playing Doom through it. There are a definitely going to be heck of a lot of floating point ops every frame though, so if those can be accelerated at all I imagine it would be a nice optimization.
I haven't thought a ton about the emulation side lately, but those glitches did send me down the rabbit hole of ways to improve the rendering situation in general, so I've been doing a few experiments − the first being a hack to replace the game's existing (but unused in OpenGL) attempt at a vertex buffer implementation: the idea being that if the game doesn't need to submit the mesh data and indices every frame, it should reduce possible incidence of corruption where there's some indirection in communication of that memory to the GPU, as well as at least marginally reducing render time. This turned out to be a... nominal success, as I learned how the meshes were originally being handled and was able to get it working as expected (with the exception of occasionally missing vertices on models with multiple LOD levels, which likely meant I was a few bytes off somewhere) on shapes and did even see a difference in render time...
What pretty quickly became clear though was that the biggest drain on render time when it came to individual shapes was down to neither simply resubmission of data every frame nor purely the fixed pipeline, rather the mammoth number of draw calls. For something like a player shape, which is a composite of a series of meshes with individual rotations, there are by default I believe around 250 draw calls; the standard format reads the mesh of each component of a player model into between 4 and 20 triangle strips, each of which has its own glDrawElements call. For most general object shapes the number is obviously much lower (I haven't looked at specific objects, but particularly those without animations should be only a handful of strips), but still not insignificant when the number of objects starts to add up. There are also many more GL calls setting/resetting general state (things like submitting the lights that should contribute to the object, view matrices, texture envs, culling/blending/depth settings, etc) between each object being rendered which could potentially be optimized to maintain commonalities, but since the driver should queue those up prior to submission their actual impact on render time should already be relatively minimal.
The game does have support for converting meshes from multiple strips to single strips (enabled by setting the bool pointed to by **0x9ECEFB to true) which can somewhat reduce the number of draw calls relatively trivially, though there may be drawbacks/limits to the conversion. An alternative to this to keep it down to one draw call for each component part (or multiple sharing the same transform matrix) could be to just add a new way to batch up the indices that'd normally be submitted by the multiple draw calls for the different primitives and do it in one, which should cut a player object render down to 20-25 draw calls. Getting it down to rendering the whole player/object in one draw call should be possible, but only if fully replaced and running through a shader program, and then only if either the vertices for each component are pre-multiplied by their respective matrices each frame OR if a buffer of indexed matrices for each submesh of the shape is submitted to the program to be multiplied in the vertex shader, which is probably the optimal solution. Hell, going the shader route it should even be possible to instance static shapes and render a mountain of spam with one draw call if there's a buffer/texture the shader can read their unique aspects from.
The experiment also exposed a few problems with both the interior and terrain rendering systems when the game saw vertex buffer support was enabled, largely because their expected behaviour for a vertex buffer seemed to work on the assumption that it'd be working on some intermediate buffer before later submission (which I assume the d3d wrapper must've been doing); the software terrain tessellation was set so for every tile it'd bind the vertex buffer and modify the vertex data for detail levels depending on distance, causing it to attempt to sync the GPU memory some ridiculous number of times each frame, which absolutely murders the framerate. Interiors have a few different render modes based on feature set, and are generally efficient in most cases because the portaling works well to ensure only what's needed is rendered, but it's putting a lot of it together on the fly, and they ended up doing some things multipass at the time, even using heavier direct-mode glBegin/glEnd sections for drawing things like environment maps and dynamic lights.
I didn't want to bother dealing with going deep either of these at the time, so I disabled one piece of the interior rendering that was killing perf, then hooked the terrain rendering to just shut it off while testing... but that lead to the next experiment:
Hacked-on hardware-optimized terrain rendering. Before anyone gets too excited, I'd preface this to disclaim that this is at this stage primarily a project for the benefit of my own learning process; it's fairly slow going with a lot of trash scratch code and it probably won't be ready to go out in the wild any time soon.
The dirty rundown:
The framerates in some of the shots aren't necessarily representative of the render time for the terrain itself: the counters being read only have 1ms tick precision, the minimum time between frame execution is 1ms, and everything else on the main thread still runs first. Basically what you see is some frames are complete in one millisecond and others in two. That said, without having done more detailed profiling, the bottom line is that the largest terrains are at this stage rendering in far less than 0.5ms where at stock on the same hardware and resolution the same views could easily take 4-5+ ms to render. The difference would likely be more drastic where CPU time or GPU I/O is a bigger bottleneck.
Some of the remaining pieces to eventually make this useful: loading in the materials (both near and distant, so possibly pre-processing so fewer samples are required on distant terrain), precomputing ambient occlusion/self-shadowing, basic environment lighting/shadows, terrain holes.
The engine's software blender supports up to 8 materials in a terrain (although the editor might only show 6), with the 4 highest weights for a given position being allowed to contribute to a pixel. This should be relatively straightforward to implement in GLSL, but it might be necessary to load and handle the materials outside of the existing texture manager ecosystem to avoid issues and maybe support new formats. There's also an interesting possibility of using the original concept of material lists specifying different terrain tile variants for each texture, which the game currently doesn't do but many of the original maps were designed for.
Some of the other precomputation bits should be easy, just where it's better done on the GPU they'll need framebuffers and shaders set up. As for terrain holes, well, it's a single mesh, so an index lookup in the shader to discard the vertices or fragments might be the only option, likely through some flags packed in one of the maps.
A full new solution to the lights and shadows contributed by dynamic objects though... that's likely to be a bigger undertaking. Both dynamic lights and shadows cast by moving objects (as well as projectile impact decals and the like) are in the standard game individually drawn meshes for each light or shadow, and these aren't efficient to render nor do they map well to a terrain that won't necessarily fully match the collision mesh. There are a lot of different approaches that could be taken here, and I've read papers on a handful of them, but haven't decided on trying anything specific yet.